Pushing the limits of remote RF sensing by reading lips under the face mask
This paper in Nature Communications solves the fundamental limitations of camera-based systems by proposing a remote radio frequency (RF) based lip-reading framework, with an ability to read lips under face masks. The system preserves privacy by collecting only radio-frequency data, with no accompanying video footage.
DOIDataset: Pushing the Limits of Remote RF Sensing: Reading Lips Under Face Mask
The dataset is about reading lips in a privacy preserving manner. In particular, radio frequency (RF) sensing was used to capture unique channel variation due to lip movements. USRP x300 was utilised equipped with the VERT2450 omnidirectional antenna and HyperLOG 7040 X used for reception and transmission respectively. Further, the same experiment was repeated with a Xethru UWB radar, where doppler frequency shifts due to lip movements are captured. We consider six classes for lip movements. Five vowels (a, e, i, o, u) and one empty class where lips were not moving. We are able to read lips even under face masks. Three subjects 1 male and 2 females participated in the experiments.
DownloadDataset: Intelligent Wireless Walls for Contactless In-Home Monitoring
The dataset is about monitoring human activities in complex Non-line-of-sight (Non-LOS) environments. Radio frequency (RF) sensing was employed in particular to collect unique channel fluctuations induced by multiple activities. The data collection hardware consists of two USRP devices one used as a transmitter (Tx) and one as receiver (Rx). Both USRPs are placed in a position where Tx and Rx were not in LOS. One was corner scenario, and the other was multifloor scenario. In the corner scenario, Tx was in one corridor while the Rx was in the other corridor and reflecting intelligent surface (RIS) was placed at corner to steer the beam towards the subject. The activities were performed between Tx and RIS. In multifloor scenario, Tx was on 5th floor and Rx was 3rd floor along with RIS. Activities were performed between RIS and Rx. Two subjects participated in experiments where each activity was performed for 6 seconds. The considered activities were sitting, standing, walking and empty.
DownloadDataset: 5G-Enabled Contactless Multi-User Presence and Activity Detection for Independent Assisted Living
The dataset represents a combination of activities captured through wireless channel state information, using two USRP X300/X310 devices, to serve a system that was designed to detect presence and activities amongst multiple subjects. The dataset was divided into 16 classes, each represents a particular number of subjects and activities. More details can be found in the readme file.
DownloadDataset: Non-invasive Localization using Software-Defined Radios
The dataset is about locating human activities in an office environment. Radio frequency (RF) sensing was employed in particular to collect unique channel fluctuations induced by multiple activities. The data collection hardware consists of two USRP devices that communicate with each other when activity takes place inside their coverage region. The USRPs are based on the National Instrument (NI) X310/X300 models, which are connected to two PCs by 1G Ethernet connections and have extended bandwidth daughterboard slots that cover DC–6 GHz and up to 120 MHz of baseband bandwidth. The two PCs were equipped with Intel(R) Core (TM) i7 7700.360 GHz processors, 16 GB RAM, and the Ubuntu 16.04 virtual operating system. For wireless communication, the USRPs were equipped with VERT2450 omnidirectional antennae. One participant performed in a room environment for the duration of the experiment, collecting 4300 samples for seven different activities in three zones and locations.
DownloadTowards Robust Real-time Audio-Visual Speech Enhancement

Abstract: The human brain contextually exploits heterogeneous sensory information to efficiently perform cognitive tasks including vision and hearing. For example, during the cocktail party situation, the human auditory cortex contextually integrates audio-visual (AV) cues in order to better perceive speech. Recent studies have shown that AV speech enhancement (SE) models can significantly improve speech quality and intelligibility in very low signal to noise ratio (SNR) environments as compared to audio-only SE models. However, despite significant research in the area of AV SE, development of real-time processing models with low latency remains a formidable technical challenge. In this paper, we present a novel framework for low latency speaker-independent AV SE that can generalise on a range of visual and acoustic noises. In particular, a generative adversarial networks (GAN) is proposed to address the practical issue of visual imperfections in AV SE. In addition, we propose a deep neural network based real-time AV SE model that takes into account the cleaned visual speech output from GAN to deliver more robust SE. The proposed framework is evaluated on synthetic and real noisy AV corpora using objective speech quality and intelligibility metrics and subjective listing tests. Comparative simulation results show that our real time AV SE framework outperforms state-of-the-art SE approaches, including recent DNN based SE models.
PDFTowards Intelligibility-Oriented Audio-Visual Speech Enhancement

Abstract: Existing deep learning (DL) based speech enhancement approaches are generally optimised to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in real noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions and integration of audio-visual (AV) information for more robust speech enhancement (SE). In this paper, we introduce DL based I-O SE algorithms exploiting AV information, which is a novel and previously unexplored research direction. Specifically, we present a fully convolutional AV SE model that uses a modified short-time objective intelligibility (STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of AV modalities with an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed I-O AV SE framework outperforms audio-only (AO) and AV models trained with conventional distance-based loss functions, in terms of standard objective evaluation measures when dealing with unseen speakers and noises.
PDFGitHubCochleaNet: A robust language-independent audio-visual model for real-time speech enhancement

Abstract: Noisy situations cause huge problems for the hearing-impaired, as hearing aids often make speech more audible but do not always restore intelligibility. In noisy settings, humans routinely exploit the audio-visual (AV) nature of speech to selectively suppress background noise and focus on the target speaker. In this paper, we present a novel language-, noise- and speaker-independent AV deep neural network (DNN) architecture, termed CochleaNet, for causal or real-time speech enhancement (SE). The model jointly exploits noisy acoustic cues and noise robust visual cues to focus on the desired speaker and improve speech intelligibility. The proposed SE framework is evaluated using a first of its kind AV binaural speech corpus, ASPIRE, recorded in real noisy environments, including cafeteria and restaurant settings. We demonstrate superior performance of our approach in terms of both objective measures and subjective listening tests, over state-of-the-art SE approaches, including recent DNN based SE models. In addition, our work challenges a popular belief that scarcity of a multi-lingual, large vocabulary AV corpus and a wide variety of noises is a major bottleneck to build robust language, speaker and noise-independent SE systems. We show that a model trained on a synthetic mixture of the benchmark GRID corpus (with 33 speakers and a small English vocabulary) and CHiME 3 noises (comprising bus, pedestrian, cafeteria, and street noises) can generalise well, not only on large vocabulary corpora with a wide variety of speakers and noises, but also on completely unrelated languages such as Mandarin.
PDFDOIASPIRE CorpusContextual deep learning-based audio-visual switching for speech enhancement in real-world environments

Abstract: Human speech processing is inherently multi-modal, where visual cues (e.g. lip movements) can help better understand speech in noise. Our recent work [1] has shown that lip-reading driven, audio-visual (AV) speech enhancement can significantly outperform benchmark audio-only approaches at low signal-to-noise ratios (SNRs). However, consistent with our cognitive hypothesis, visual cues were found to be relatively less effective for speech enhancement at high SNRs, or low levels of background noise, where audio-only (A-only) cues worked adequately. Therefore, a more cognitively-inspired, context-aware AV approach is required, that contextually utilises both visual and noisy audio features, and thus more effectively accounts for different noisy conditions. In this paper, we introduce a novel context-aware AV speech enhancement framework that contextually exploits AV cues with respect to different operating conditions, in order to estimate clean audio, without requiring any prior SNR estimation. In particular, an AV switching module is developed by integrating a convolutional neural network (CNN) and long-short-term memory (LSTM) network, that learns to contextually switch between visualonly (V-only), A-only and both AV cues at low, high and moderate SNR levels, respectively. For testing, the estimated clean audio features are utilised using an innovative, enhanced visually-derived Wiener filter (EVWF) for noisy speech filtering. The context-aware AV speech enhancement framework is evaluated in dynamic real-world scenarios (including cafe, street, bus, and pedestrians) at different SNR levels (ranging from low to high SNRs), using benchmark Grid and ChiME3 corpora. For objective testing, perceptual evaluation of speech quality (PESQ) is used to evaluate the quality of the restored speech. For subjective testing, the standard mean-opinion-score (MOS) method is used. Comparative experimental results show the superior performance of our proposed context-aware AV approach, over A-only, V-only, spectral subtraction (SS), and log-minimum mean square error (LMMSE) based speech enhancement methods, at both low and high SNRs. The preliminary findings demonstrate the capability of our novel approach to deal with spectro-temporal variations in real-world noisy environments, by contextually exploiting the complementary strengths of audio and visual cues. In conclusion, our contextual deep learning-driven AV framework is posited as a benchmark resource for the multi-modal speech processing and machine learning communities.
PDFDOICogAVHearing Lip-Reading Driven AV Speech Enhancement Demo
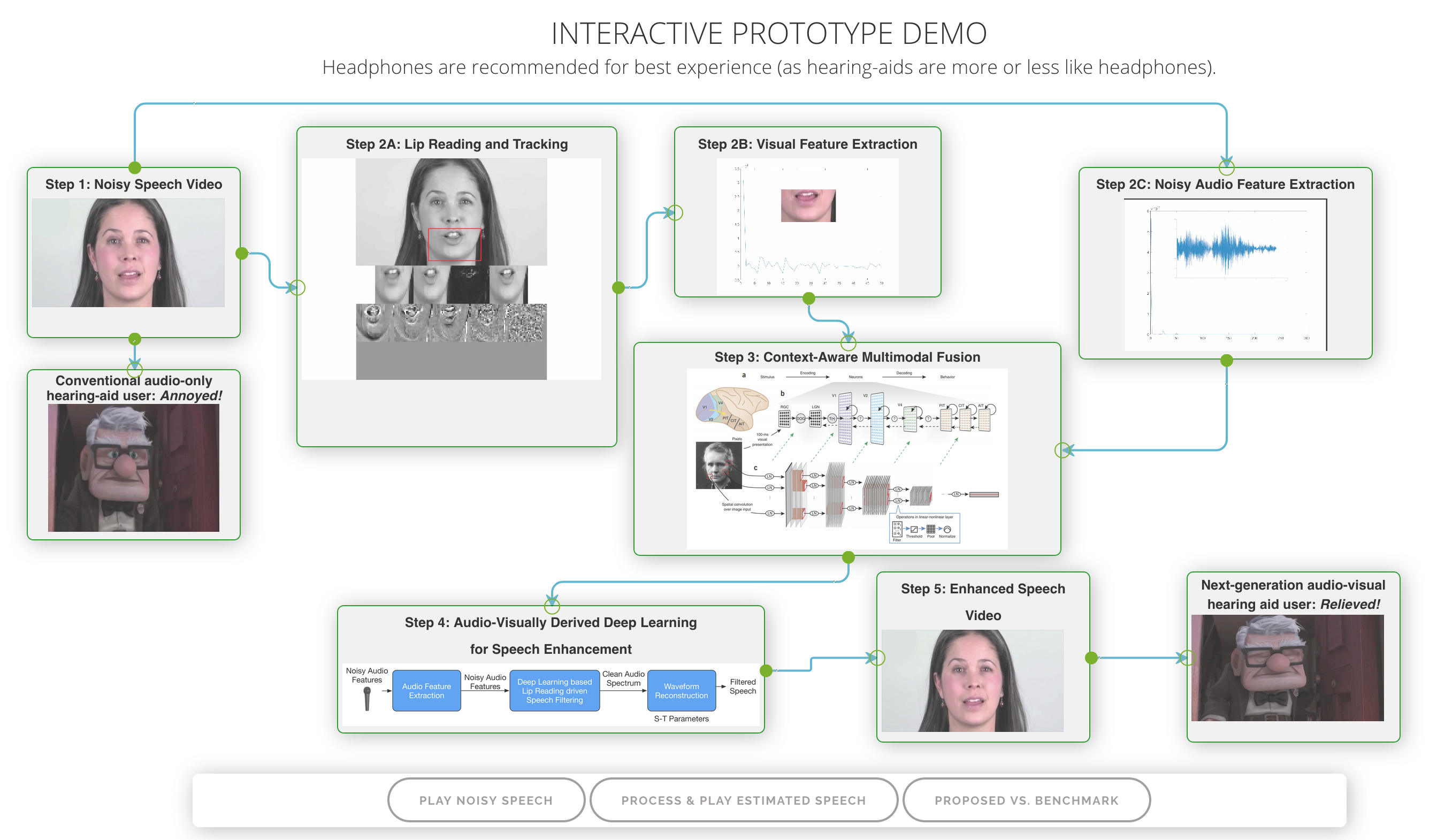
This preliminary interactive Demo is aimed at demonstrating the potential of "context-aware" audio-visual hearing aids, based on Big Data Deep Learning technology. The demo has been developed by feeding randomly selected, real noisy speech videos from YouTube, into the audio-visual speech enhancement system.
Demo Link